ここまでの記事で、Rのプログラミングの基本骨格が何となく見えてきたんじゃないかな~と思うんだ。そこで、今回の記事では、インターネットでサンプルコードを探して、それを真似して自分でコードを書くときに、僕がどんな流れでプログラミングをしているかを紹介するね。
この記事のポイント
【実施例】サンプルコードを探して散布図のグラフを描く流れ
じゃあ、ここではRのサンプルデータの “Puromycin” をつかって散布図を描くという課題を例に、僕がどんな感じでインターネット上のサンプルコードを探したり、コードを真似したりするか紹介するね!
Rのコードを検索してみよう!
どんな風にコードを書いたらいいのかわからない解析の場合には、まずはGoogleなどでRのコードを検索しよう!どんなワードで検索してもいいけれど、単純なコードなら “iris” のようなサンプルデータの名前を入れて検索すると、データの中身が分かっているからおすすめだよ!
たとえば、”iris”, “scatter plot”, “R” で画像検索を行うと下記のように iris のサンプルデータを使った散布図が出てくるよ!ちなみに図を描くのであれば、画像検索をするのがおすすめだね!

この中で、自分が描きたい図とイメージが近いページを見てみよう!
Rのコードをそのまま出力してみよう
今回は2番目に出てきたグラフのウェブサイトを参考にするよ!
ページを下にスクロールしていくと、検索画面に出てきた画像と同じ画像が出てくるんだけど、その前に下記のコードが出てくるよ。
# A scatter plot that shows the points in groups according to their "species"
plot(Petal.Width ~ Petal.Length, data=iris,
col=c("brown1","dodgerblue1","limegreen")[as.integer(Species)],
pch=c(1,2,3)[as.integer(Species)])
legend(x="topleft",
legend=c("setosa","versicolor","virginica"),
col=c("brown1","dodgerblue1","limegreen"),
pch=c(1,2,3))
まずは、これを見つけよう!このコードをそのままRのコンソール画面に出力すると、下記のように同じ画像を描けるよ。(縦横比など、細かい点は違いがあるけどそこは気にしないでOK)

グラフが普通に描けたら、サンプルコードに間違いがないってことなので、まずはこのサンプルコードを理解していこう!
コードの中身をチェックしよう!
まず前半の下記の部分だけ出力すると凡例のないグラフが出力されるよ。
plot(Petal.Width ~ Petal.Length, data=iris,
col=c("brown1","dodgerblue1","limegreen")[as.integer(Species)],
pch=c(1,2,3)[as.integer(Species)])
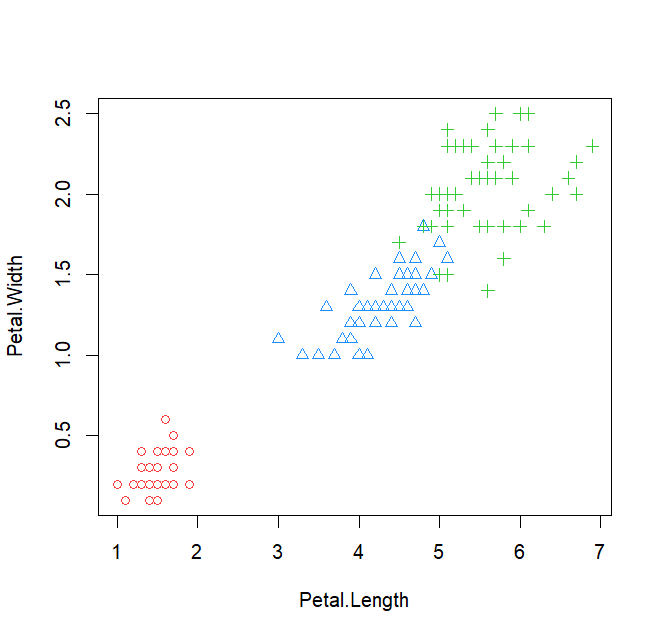
つまり、このプログラミングコードでグラフが描けて、後半のプログラミングコードで凡例を記載するという流れなんだね。
また、このコード全体は、 plot( ) という構造になっているんだけど、これは、関数だったね!plot関数という関数で散布図が描けるっていうこと。つぎにPetal.Width ~ Petal.Lengthと記載があって、これはY軸のデータ、X軸のデータを表しているのは分かるかな?さらに、 data = iris と記載があるけれど、この = は関数の中に含まれている = になるので、オブジェクトを指定するときのイコールになるよ。つまり、 iris というサンプルデータを指定しているんだね。
こんな感じでサンプルコードの中身をチェックして一つ一つを理解すると、自分でも真似することができるよ!一応、ぼくが説明を加えるとしたらこのサンプルコードは下記のような感じ。こんな風に分解することでコードをまねすることができるよ!
# plot関数で散布図を描く
plot(
# y軸はPetal.Width, x軸はPetal.Length
Petal.Width ~ Petal.Length,
# もとのデータはiris (Rに含まれるサンプルデータ)
data=iris,
# オプションのcolでポイントの色を指定, as.integerで品種名を数値化
col=c("brown1","dodgerblue1","limegreen")[as.integer(Species)],
# オプションのpchでポイントの形を指定, as.integerで品種名を数値化
pch=c(1,2,3)[as.integer(Species)]
)
# legend関数で散布図に凡例を追加する
legend(
# オプションのxで凡例の場所を指定
x="topleft",
# オプションのlegendで凡例の名前を指定
legend=c("setosa","versicolor","virginica"),
# オプションのcolで凡例のポイントの色を指定
col=c("brown1","dodgerblue1","limegreen"),
# オプションのpchで凡例のポイントの形を指定
pch=c(1,2,3)
)
ちなみに、このコードの中でちょっとトリッキーなポイントは [as.integer(Species)] っていうところ。これは、as.integerという関数でirisのSpeciesの列をfactor型から1~3の数字に変換しているんだ。そして、”col =” のときには1は “brown1”, 2は “dodgerblue1”, 3は “limegreen” という色になるように指定しているというわけ。”pch =” のときにはポイントの形を1, 2, 3に指定していて、Rのデフォルト設定でそれぞれ〇、△、+のポイントの形になるんだ。
ちょっと難しかったかもしれないけれど、ここまでの作業がとっても大事!こんな感じでサンプルコードを見つけてきて、中身を分解していく作業を行えば、あとは自分でまねするだけだよ!
サンプルコードを参考に自分でコードを書いてみよう!
いよいよ最後、サンプルコードを参考に自分で書いてみよう!じゃあ、コードを書く前に、 Promycinっていうサンプルデータがどんなデータなのか確認してみよう。データの確認方法は色々あるけれど、今回はtibble関数を使うよ!
> install.packages("tidyverse")
> library(tidyverse)
> tibble(Puromycin)
# A tibble: 23 x 3
conc rate state
<dbl> <dbl> <fct>
1 0.02 76 treated
2 0.02 47 treated
3 0.06 97 treated
4 0.06 107 treated
5 0.11 123 treated
6 0.11 139 treated
7 0.22 159 treated
8 0.22 152 treated
9 0.56 191 treated
10 0.56 201 treated
# ... with 13 more rows
“Puromycin” というサンプルデータは抗生物質の1つピューロマイシンを処理または未処理の細胞の酵素反応の反応速度のデータだよ。concは基質の濃度、rateは酵素反応の速度を表していて、treatedとuntreatedはピューロマイシン処理の有無を表しているよ。
y軸にconc、x軸にrateを出力し、ポイントの色と形をstateの列で分けるようにしよう!つまり、サンプルコードを下記のように書きかえるんだ。
- iris → Puromycin
- Petal.Width → conc
- Petal.Length → rate
- Species → state
これでもとのサンプルコードは下記のようになるよ。
# plot関数で散布図を描く
plot(
# y軸はconc, x軸はrate
conc ~ rate,
# もとのデータはPuromycin (Rに含まれるサンプルデータ)
data=Puromycin,
# オプションのcolでポイントの色を指定, as.integerで品種名を数値化
col=c("brown1","dodgerblue1","limegreen")[as.integer(state)],
# オプションのpchでポイントの形を指定, as.integerで品種名を数値化
pch=c(1,2,3)[as.integer(state)]
)
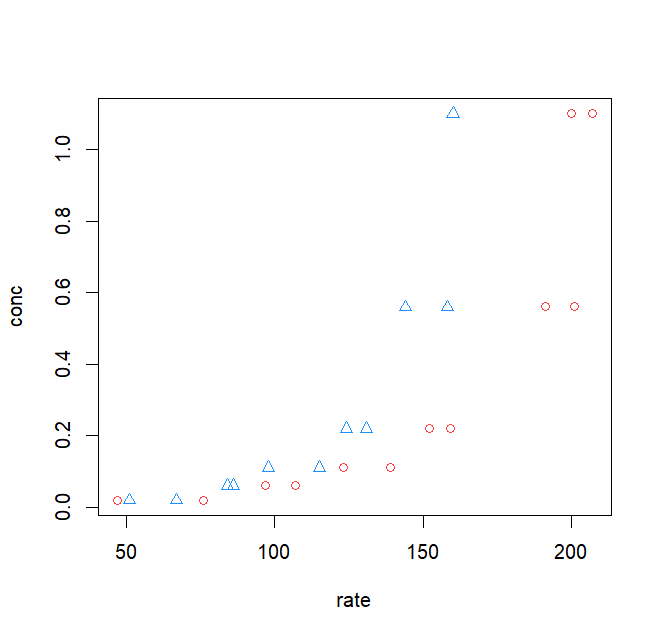
すると、上の図ように、なんとなく正しそうなグラフが出力されたね!こんな感じで、凡例までコードを書きあげるんだ!irisとPuromycinのデータで異なる点として、irisにはポイントの色や形は3つあるのに対して、Promycinでは2つしかない。だから、3つ目の色(limegreen)と3つ目のポイントの形(3)は消してしまってOKだよ。
# plot関数で散布図を描く
plot(
# y軸はconc, x軸はrate
conc ~ rate,
# もとのデータはPuromycin(Rに含まれるサンプルデータ)
data=Puromycin,
# オプションのcolでポイントの色を指定, as.integerで品種名を数値化
col=c("brown1","dodgerblue1")[as.integer(state)],
# オプションのpchでポイントの形を指定, as.integerで品種名を数値化
pch=c(1,2)[as.integer(state)]
)
# legend関数で散布図に凡例を追加する
legend(
# オプションのxで凡例の場所を指定
x="topleft",
# オプションのlegendで凡例の名前を指定
legend=c("treated","untreated"),
# オプションのcolで凡例のポイントの色を指定
col=c("brown1","dodgerblue1"),
# オプションのpchで凡例のポイントの形を指定
pch=c(1,2)
)

ってな具合でめでたく、目的のグラフを書き上げることができたよ!こんな流れでサンプルコードを参考に自分でコーディングしていくうちに、少しずつできる解析が増えていくよ!
サンプルコードの集め方
さいごにサンプルコードの集め方をいくつか紹介しよう。基本的にはGoogleで検索して上位表示されているwebサイトであれば、分かりやすいサイトが表示されると思うけれど、その他にこんな調べ方があるよ!っていうのを紹介するよ!
RStudio Cheatsheet

RStudioのウェブサイトにチートシートというものが転がっているんだ。これは、プログラミングコードを1~2枚のPDFにまとめたファイルでめちゃくちゃ有用だよ!
実はRStudio社はRStudioのソフトウェアだけでなくRのパッケージも色々と開発していて、その代表的なものがtidyverseというメタパッケージでdplyrやggplot2といったものなんだ!こういったRStudio社が開発したパッケージのコードはほぼまんべんなくチートシートが公開されていて、RStudio社が開発したパッケージ以外のチートシートも色々と公開されているので、まずはこれを参考に使おう!
Qiita

Qiitaはプログラミングに関する投稿サイトだよ。記事の内容や質にはバラツキはあるんだけど、とにかく投稿数が多いことと総じて記事が見やすいです。アカウントを作っておくと、参考にしたページをストックできたりするので、どのくらい使うかはともかくとして、とりあえずアカウントを持っておいても損はないと思うよ!
論文などに掲載されるコード
機械学習などを行う人は参考にする論文のData avalabilityなどにコードの公開情報がのっていることがあるよ!本格的にプログラミングを始めるときにはこれはとっても貴重な情報になるよ!だって、サンプルコードと違って、本物のガチコードだからね!サンプルコードだとうまくいってるのに、実際のデータを動かしてみたらエラーになってしまうなんてときに、どんな風に対処しているのかなど、とっても参考になるよ!
さいごに
今回の記事で、大まかにRでプログラミングを行う流れまでを紹介できたよ!今までの記事をていねいに読んできたみんなは自信をもってRを使い始めてもいいと思うよ!ただ、そうは言っても、最初はちょっとしたコードを書くだけでもメチャクチャ時間がかかってしまうので慣れるまではやっぱり大変だと思うから、そこはめげずに頑張ろう!
初心者でとにかくコードの構造を確認しないで、手当たり次第にコピペしながらコードを書く人がいますが、その癖がついてしまうと、複雑なコードになってきたときに「どうしよう??」ってなっちゃうので、なるべく単純なコードを書くときから構造の理解を意識するといいと思うよ!
また、コードを書くときに、プログラムの途中で改行を適宜入れ、必要に応じて "#" 記号を使用しながら説明書きを残す癖をつけると良いと思います。とにかく、自分にとって分かりやすくなるように工夫しながら、コードを書いて行きましょう!
この記事のまとめ